
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- RAG
- airflow
- 루프백주소
- BigQuery
- spark
- 설치
- dockercompose
- milvus
- Python
- pySpark
- hadoop
- 오블완
- amazonlinux
- Redshift
- docker
- aiagent
- metadabatase
- airflow설치
- javascript
- SQL
- ubuntu
- MSA
- vectorDB
- prometheus
- Streamlit
- Dag
- grafana
- jmx-exporter
- kafka
- sparkstreaming
Archives
- Today
- Total
데이터 노트
[Spark] Spark 설치 (Databricks 노트북) | PySpark 로 빅데이터 분석하기 - 2 본문
Data Engineering/Spark
[Spark] Spark 설치 (Databricks 노트북) | PySpark 로 빅데이터 분석하기 - 2
돌돌찐 2024. 9. 24. 23:07| PySpark 로 빅데이터 분석하기 with Python 강의를 수강하며 정리한 내용입니다. |
강의 촬영 시기랑 지금이랑 조금 UI적으로 바뀐 부분들이 있어서 찾아가면서 했다. (크게 다르지는 않음)
Databricks의 노트북을 사용하기 위한 세팅 방법에 대해 알아보자.
대략적인 순서
1. 계정 생성
2. 클러스터 생성
3. 노트북 생성
4. Table 생성
상세 과정
- databricks.com/try-databricks 로 접속한다.
- 접속 후 계정 생성을 한다. (꼭 회사 계정일 필요는 없으므로, 개인 이메일로 작성해도 된다.)
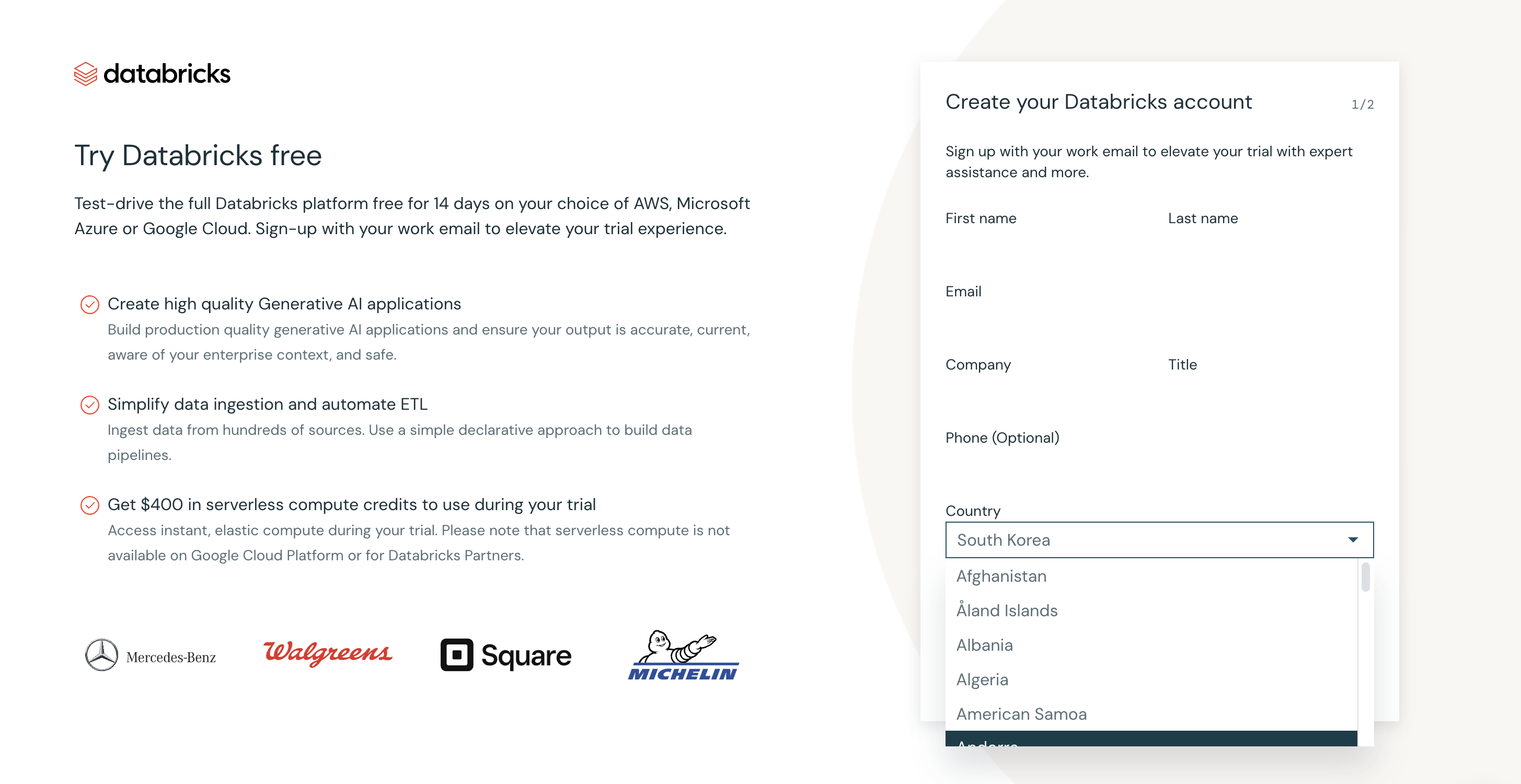
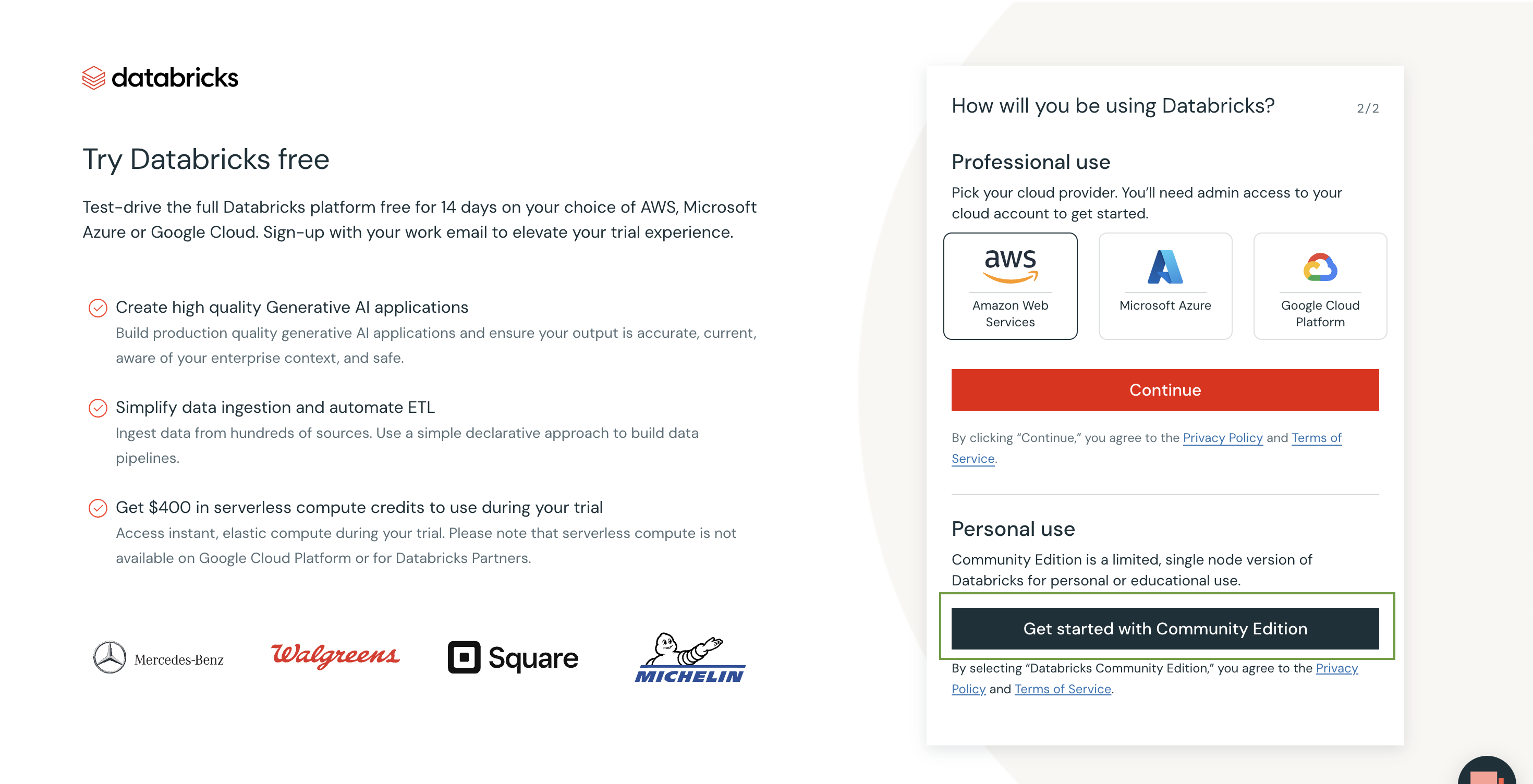
- 무료 버전으로 테스트 할 것이기 때문에, 커뮤니티 에디션으로 시작한다. (초록색 박스 부분 클릭)
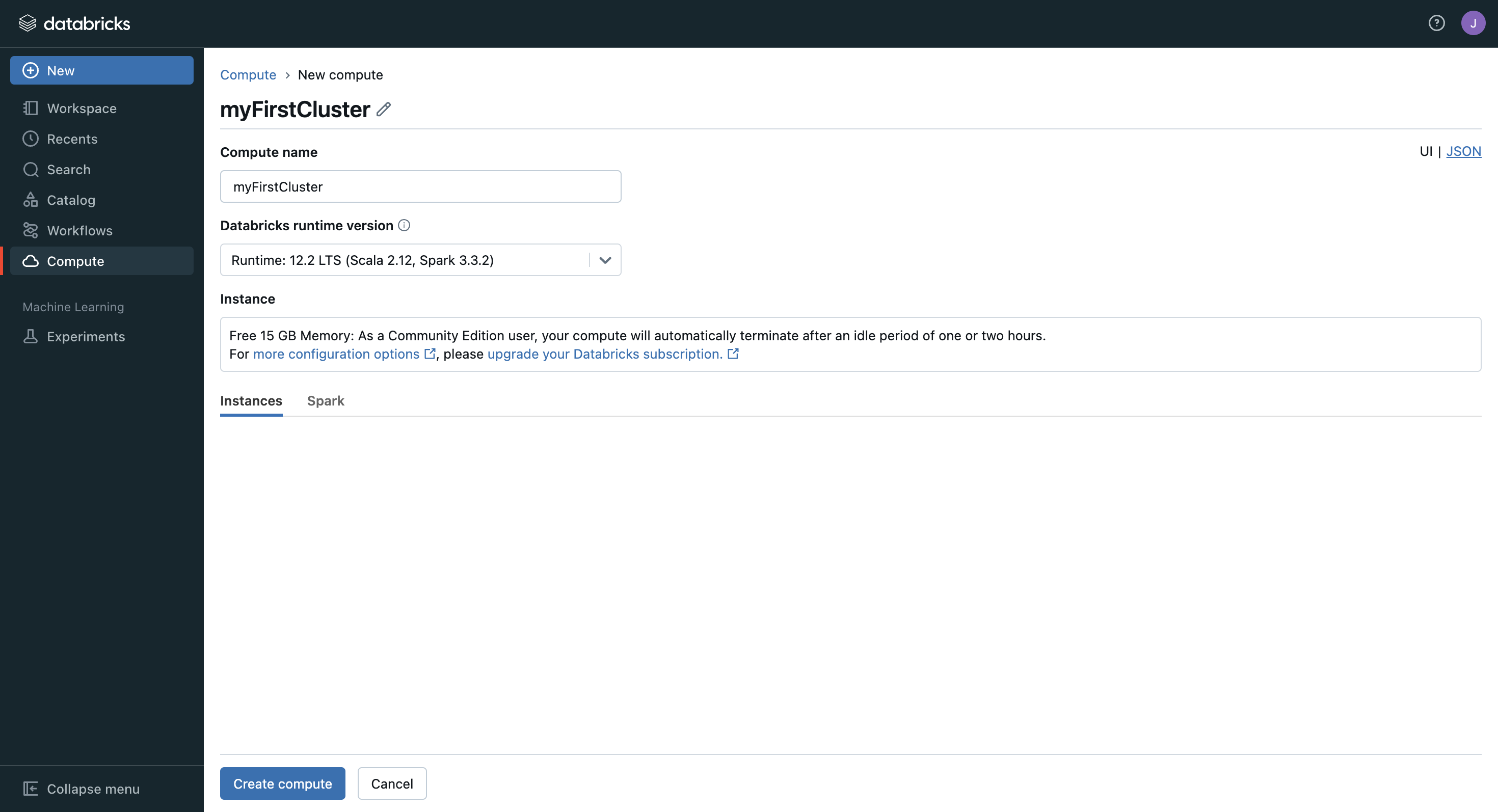
- 작업을 하기 위해 Cluster를 생성해준다. (New - Cluster 혹은 Compute - Create Compute)

- 이름을 작성해주고 Create Compute 진행한다. (Version은 바꿔주지 않았다.)
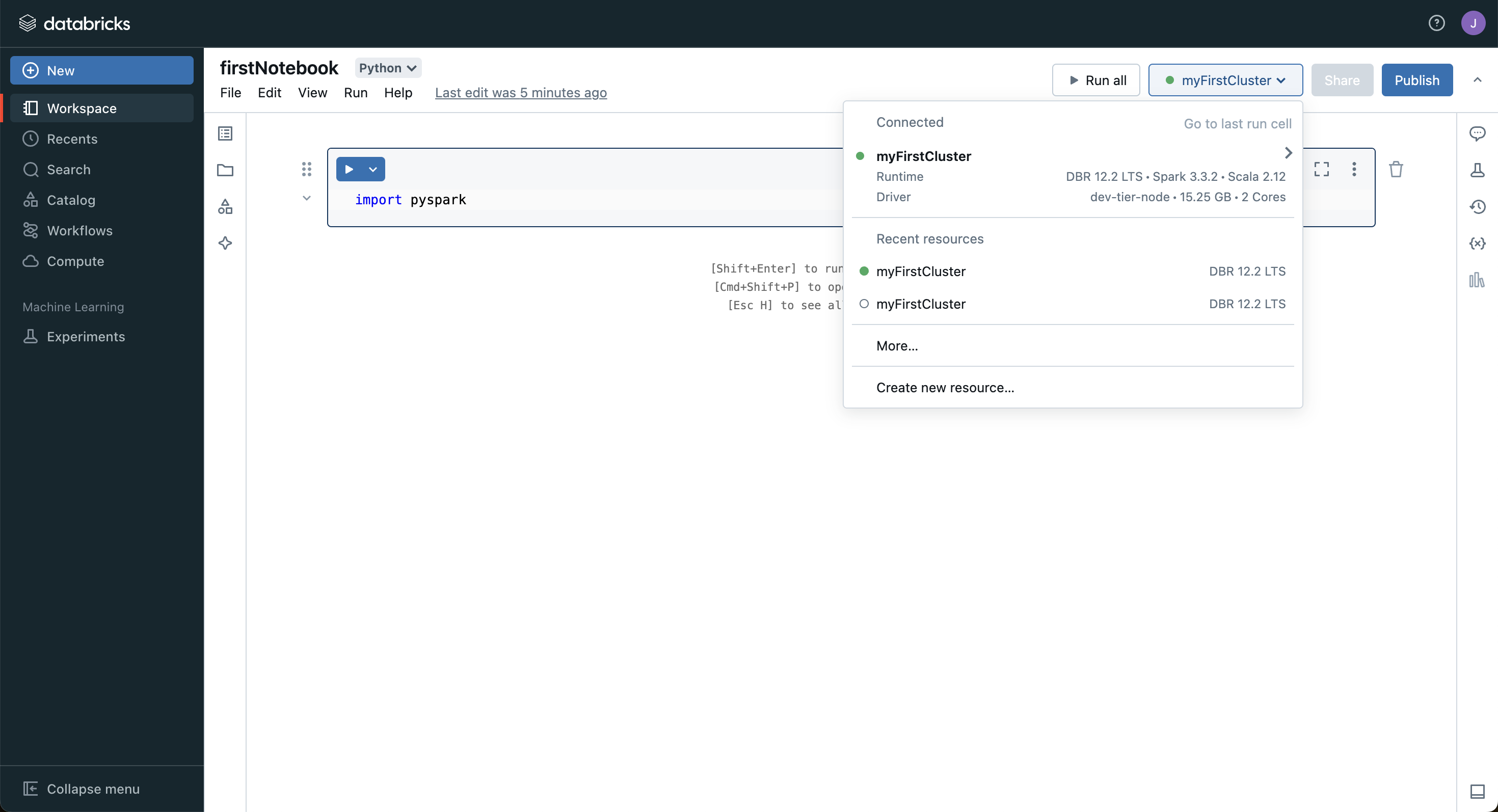
- 생성하고 나면 State가 빙글빙글 도는데, 생성이 완료되면 초록색 체크로 바뀌므로 기다렸다가 노트북을 생성한다.

- New - Notebook 에서 노트북 생성 후, 생성한 Cluster를 연결해준다.
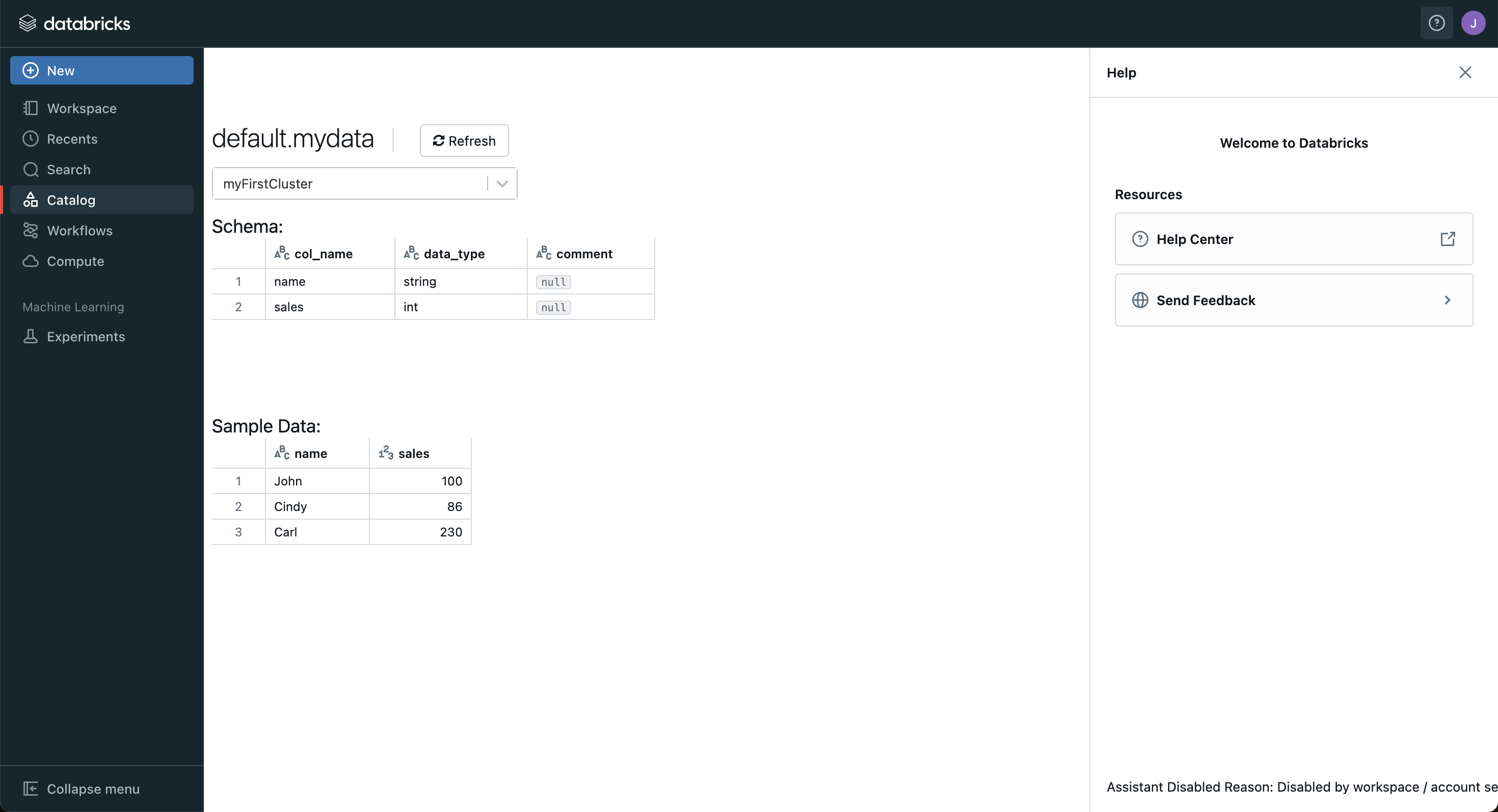
- Table도 동일하게 New - Table을 클릭한다. 이후 파일을 업로드한다.
- Table이란? : 데이터프레임의 데이터를 저장하는 곳을 말한다.
- 나는 CSV파일을 업로드 했기 때문에 Drop 했는데, S3나 DB를 연결할 수도 있다.

- 업로드 하고 나면, 데이터의 상세 설정을 할 수 있는데 데이터 컬럼 특성에 따라 변경이 필요한 부분은 변경 후 Create Table 클릭
- Spark는 첫 행을 Header로 인식하지 않는다. 여기서는 name과 sales가 헤더이므로 좌측 First row is header 체크한다.

- 프리뷰 확인
- 노트북에서 방금 입력한 테이블을 불러와 df 생성해서 출력해본다.
- sqlContext.sql로 쿼리문을 통해 조회한다.
- 보통 다른 시스템에서는 사용하려면 import sqlContext 문이 필요하지만, 데이터브릭스는 자동으로 적용해준다.
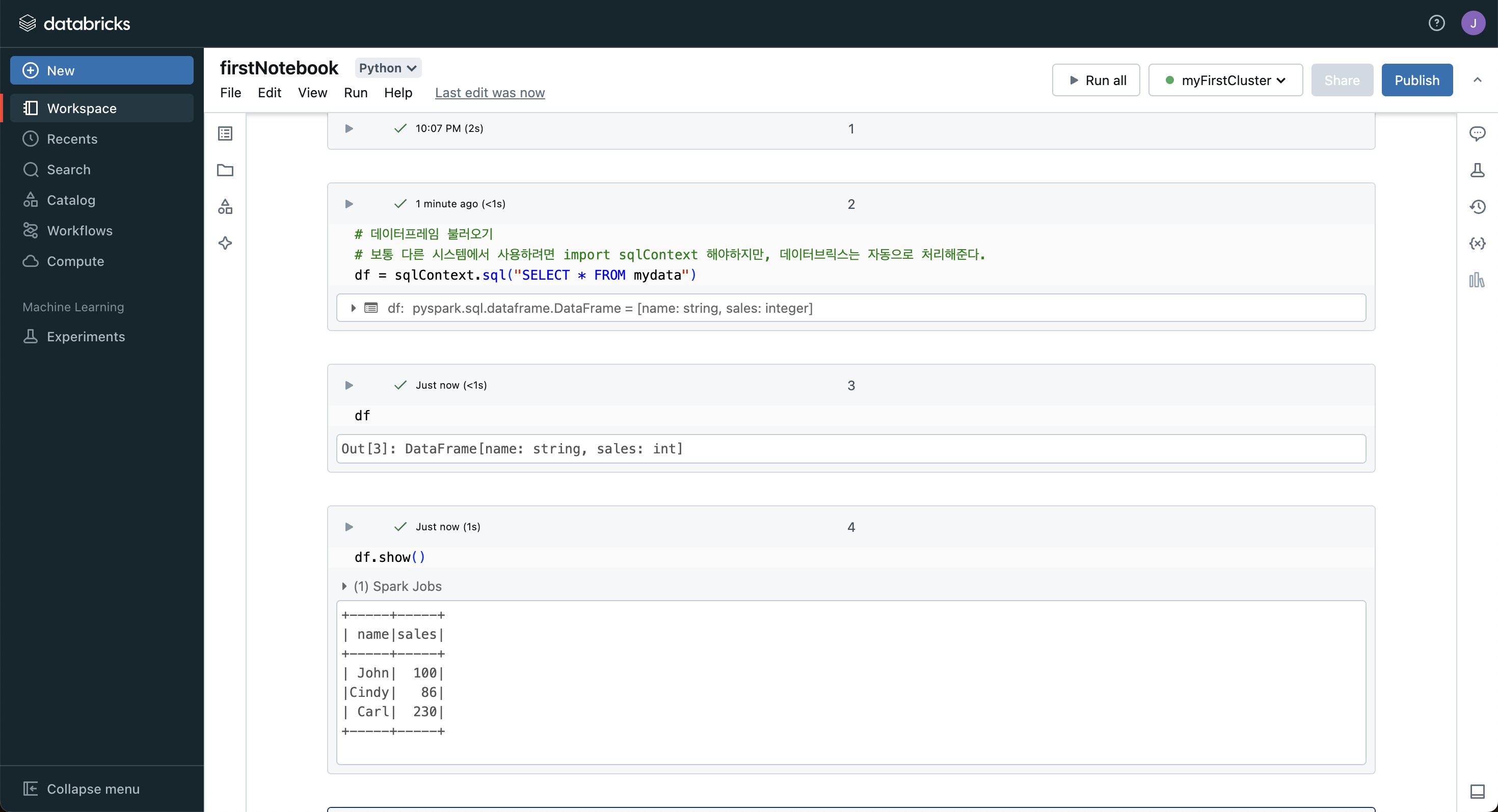
EC2에 설치해서만 사용해봤는데, 데이터브릭스 노트북은 처음!
로컬에도 설치해서 사용해보고 노트북으로도 작업해봐야겠다.
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Spark 간단 소개 | PySpark 로 빅데이터 분석하기 - 1 (0) | 2024.09.02 |
|---|
'Data Engineering/Spark' Related Articles
more
