
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- aiagent
- prometheus
- docker
- javascript
- airflow
- spark
- Dag
- 루프백주소
- grafana
- MSA
- milvus
- kafka
- 설치
- airflow설치
- RAG
- SQL
- vectorDB
- amazonlinux
- pySpark
- sparkstreaming
- Redshift
- Streamlit
- hadoop
- metadabatase
- Python
- 오블완
- dockercompose
- ubuntu
- BigQuery
- jmx-exporter
- Today
- Total
데이터 노트
[side-1] Milvus DB에 텍스트 데이터 임베딩하여 적재하기 본문
개요
분실물을 보다 용이하게 찾을 수 있도록, Lost112 사이트의 데이터를 크롤링하여 적재 후 이미지 및 텍스트 검색 기능을 붙이려고 함.
분실물 상세 페이지 내에 있는 줄글의 내용을 임베딩하여 Milvus Vector DB에 저장 후, 이후 유저가 검색 시 사용하도록 한다.
환경
ubuntu 내 docker compose로 Milvus DB와 python 코드 실행용 컨테이너를 빌드하여 데이터 적재
작업
Milvus 컨테이너 설치하기
기존에 테스트 한다고 FastAPI, Python 실행용 web_scraper 등의 컨테이너들을 이미 띄워놓았었는데,
이 docker-compose.yaml 파일에 Milvus 공식 문서에서 제공하는 내용을 추가하여 빌드했다.
아래 코드로 yaml 파일을 다운 받을 수 있다.
wget https://github.com/milvus-io/milvus/releases/download/v2.5.2/milvus-standalone-docker-compose.yml -O docker-compose.yml
sudo docker compose up -d
받으면 이러한 내용의 yaml 파일이 생성되는데, 해당 내용을 기존 docker-compose 파일에 붙여줬다.
version: '3.5'
services:
etcd:
container_name: milvus-etcd
image: quay.io/coreos/etcd:v3.5.16
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
healthcheck:
test: ["CMD", "etcdctl", "endpoint", "health"]
interval: 30s
timeout: 20s
retries: 3
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
- "9000:9000"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.5.2
command: ["milvus", "run", "standalone"]
security_opt:
- seccomp:unconfined
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
interval: 30s
start_period: 90s
timeout: 20s
retries: 3
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
networks:
default:
name: milvusMilvus에 Collection 생성하기
python 코드로 Collection을 생성해주었다. 작업은 web_scraper 컨테이너에서 진행했다.
docker exec -it web_scraper bash
pip install pymilvusfrom pymilvus import connections, Collection, FieldSchema, CollectionSchema, DataType, utility
from dotenv import load_dotenv
import os
load_dotenv()
# Milvus 연결 설정
MILVUS_HOST = os.environ.get("MILVUS_HOST")
MILVUS_PORT = os.environ.get("MILVUS_PORT")
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
# 컬렉션 스키마 정의
field_id = FieldSchema(name="item_id", dtype=DataType.VARCHAR, max_length=50, is_primary=True)
field_name = FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=255)
field_description = FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=1000)
field_embedding = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384)
schema = CollectionSchema(fields=[field_id, field_name, field_description, field_embedding], description="Lost items collection")
# 컬렉션 이름
collection_name = "lost_items"
# 컬렉션 존재 여부 확인 및 생성
if not utility.has_collection(collection_name): # 변경된 부분
collection = Collection(name=collection_name, schema=schema)
print(f"Collection '{collection_name}' created successfully.")
else:
print(f"Collection '{collection_name}' already exists.")
임베딩 값을 넣을 컬럼은 embedding으로 지정해서 Collection 생성 코드를 만들어주었다.
만들고 나서 Milvus Web UI로 확인할 수 있다.
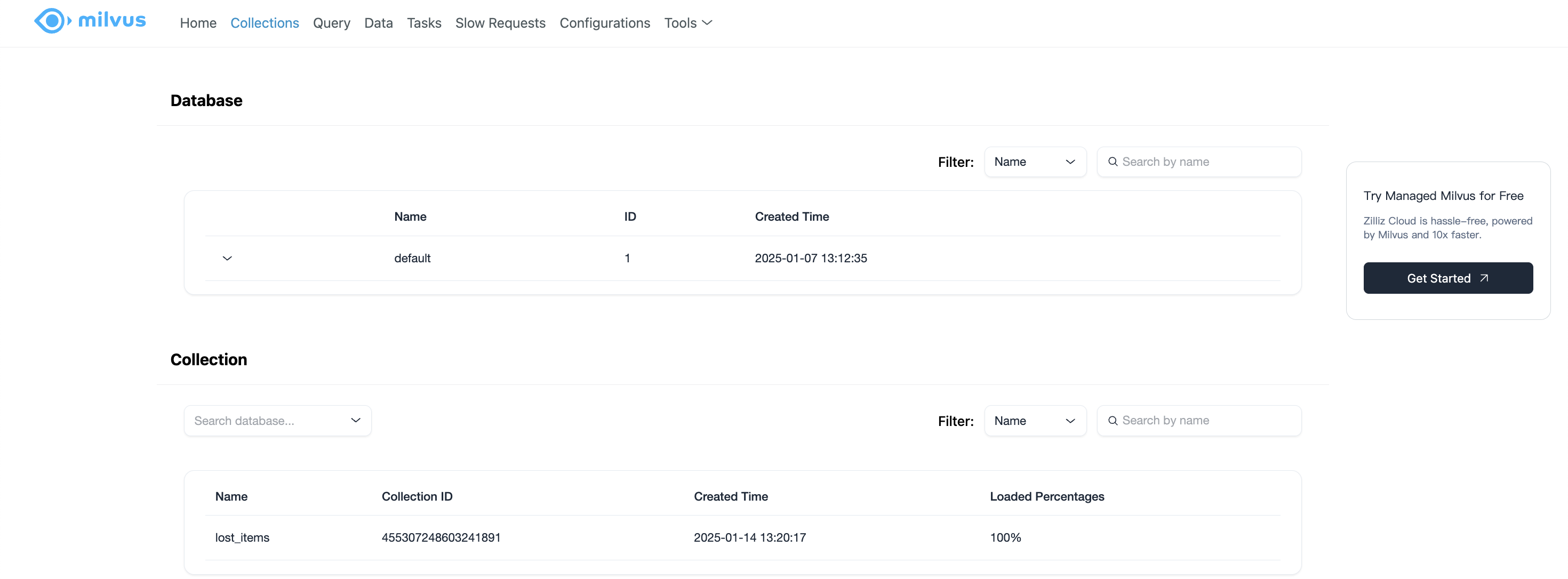
혹은 curl 명령어를 통해 확인 가능.
curl -X GET "http://localhost:9091/api/v1/collections"
{"status":{},"collection_names":["lost_items"],"collection_ids":[455148976214911510],"created_timestamps":[455149538694660106],"created_utc_timestamps":[1736257700709]}%
Collection에 데이터 적재를 하기 위한 코드 생성
우선 필요한 패키지들을 설치해준다.
pip install pandas sentence-transformers
그리고 추후에는 원천 데이터가 있는 S3나 Postgres에 text로 적재한 데이터를 가져와서 임베딩 할 예정이지만, 현재 아직 적재중이므로 csv 파일에서 필요한 내용 값만 가져와 Insert 해주었다.
import pandas as pd
from sentence_transformers import SentenceTransformer
from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)
from dotenv import load_dotenv
import os
load_dotenv()
MILVUS_HOST = os.environ.get("MILVUS_HOST")
MILVUS_PORT = os.environ.get("MILVUS_PORT")
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
df = pd.read_csv("{경로}/bag.csv")
# 임베딩 모델 로드
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
COLLECTION_NAME = "lost_items"
collection = Collection(name=COLLECTION_NAME)
# 데이터 삽입
data_to_insert = []
for _, row in df.iterrows():
item_id = row['관리번호']
name = row['습득물명']
description = row['내용']
# 관리번호, 이름, 설명 정보 모두 결합
text = f"관리번호: {item_id}, 습득물명: {name}, 내용: {description}"
embedding = model.encode(text).tolist()
data_to_insert.append([item_id, name, description, embedding])
# Milvus 데이터 삽입
if data_to_insert:
item_ids = [item[0] for item in data_to_insert]
names = [item[1] for item in data_to_insert]
descriptions = [item[2] for item in data_to_insert]
embeddings = [item[3] for item in data_to_insert]
collection.insert([item_ids, names, descriptions, embeddings])
# 인덱스 생성
if not collection.has_index():
collection.create_index(
field_name="embedding",
index_params={"index_type": "IVF_FLAT", "metric_type": "L2", "params": {"nlist": 128}}
)
collection.load()
print(f"데이터 저장 성공. collection : '{COLLECTION_NAME}'")
저장된 벡터 값을 보려면 조회하거나 attu를 통해 UI 상으로 확인할 수 있는데 나는 그 컨테이너를 띄우진 않았다.
근데 사용성이 좋아보여서 이후 추가로 설치 예정.
이후에는 사용자가 분실물 정보를 검색하면 유사한 분실물 정보를 보여주는 부분을 작업할 예정이다.
투비컨티뉴!
'Lab' 카테고리의 다른 글
| [side-1] Milvus Collection에 적재된 데이터에서 유사한 값 검색하기 (0) | 2025.01.22 |
|---|---|
| [side-1] LangChain 활용하여 RAG 구축을 위해 Milvus DB 연결 테스트 (0) | 2025.01.21 |
| [ubuntu 20.04] docker 설치하기 (0) | 2023.02.10 |
| 하둡 네임노드 에러 해결 (0) | 2023.02.10 |
| EC2에서 하둡 분산 클러스터 만들기 (0) | 2023.02.10 |


