
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- kafka
- javascript
- airflow설치
- amazonlinux
- airflow
- ubuntu
- RAG
- Python
- pySpark
- docker
- 오블완
- vectorDB
- aiagent
- sparkstreaming
- 설치
- Streamlit
- jmx-exporter
- hadoop
- dockercompose
- MSA
- grafana
- Redshift
- SQL
- spark
- 루프백주소
- Dag
- prometheus
- BigQuery
- metadabatase
- milvus
- Today
- Total
데이터 노트
Kafka, Spark, Redis를 활용한 실시간 주차장 현황 대시보드 구축하기 본문
자세한 코드 정보는 Github에!
https://github.com/JHYUNN-LEE/2025-side-MyParkingSpot
GitHub - JHYUNN-LEE/2025-side-MyParkingSpot: 서울시 실시간 주차장 현황 대시보드
서울시 실시간 주차장 현황 대시보드. Contribute to JHYUNN-LEE/2025-side-MyParkingSpot development by creating an account on GitHub.
github.com

개요
실시간 데이터 처리를 경험해보고자 했고, 데이터는 실생활에 조금 밀접한 것을 찾고자 했다.
그래서 찾게 된 실시간 주차장 현황 정보 데이터.
물론 서울시에서 여러 기업과 합작하여 더 다양한 실시간 자료를 보여주는 사이트가 운영 중이지만
나는 주차장 정보만 알고 싶었으므로 이 데이터만 가져와서 시스템을 구축해보기로 했다.
이번 프로젝트에서는 Kafka, Spark Streaming, Redis를 활용하여 실시간 주차장 데이터 스트리밍 파이프라인을 구축했다.
서울시 API에서 데이터를 가져와 Kafka를 통해 스트리밍하고, Spark Streaming으로 처리하여, Redis에 저장하고 이를 FastAPI 및 Streamlit을 통해 시각화하는 과정까지 진행해 보았다.
시스템 아키텍처
데이터 수집 (Producer)
- 서울시 실시간 도시데이터 API에서 데이터를 주기적으로 가져옴. (30초)
- Kafka Producer를 통해 데이터를 토픽으로 전송.
실시간 데이터 스트리밍 (Kafka & Spark Streaming)
- Kafka Consumer를 통해 데이터를 수신하고, Redis에 캐싱.
- Spark Streaming을 활용하여 주차장 데이터 변화 감지.
저장 & 관리 (Redis)
- Kafka Consumer가 데이터를 Redis에 저장.
- 주차 가능 공간의 변화를 감지하여 업데이트.
API 제공 (FastAPI)
- Redis에 저장된 데이터를 FastAPI를 통해 제공.
데이터 시각화 (Streamlit)
- FastAPI에서 제공하는 데이터를 기반으로 실시간 대시보드 구축.
구현 과정
docker 컨테이너 빌드
사실 이 프로젝트를 하기 전 다른 실시간 데이터 수집 관련 프로젝트를 조금 진행했었는데, 그 때 썼던 구조에서 활용해서 작성했다.
아래 yaml 파일에는 있으나, 이번 프로젝트에서는 postgresDB에 데이터를 저장하는 단계는 없으니 참고!
- docker-compose.yaml
- producer / consumer 용 각 1대씩, 브로커 3대를 올렸다.
- 테스트로 지역을 하나 설정하고 실시간으로 받아보는 형태로 진행했기 때문에 데이터의 양이 방대하진 않아서 컨슈머를 더 늘리진 않았다.
-
더보기services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "2181:2181"
healthcheck:
test: ["CMD", "nc", "-z", "localhost", "2181"]
interval: 30s
retries: 5
start_period: 5s
kafka1:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
hostname: kafka1
container_name: kafka1
ports:
- "9093:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka1:29092,PLAINTEXT_HOST://localhost:9093
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
healthcheck:
test: ["CMD", "kafka-topics.sh", "--bootstrap-server", "localhost:9092", "--list"]
interval: 30s
retries: 5
start_period: 5s
kafka2:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
hostname: kafka2
container_name: kafka2
ports:
- "9094:9092"
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka2:29092,PLAINTEXT_HOST://localhost:9094
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
healthcheck:
test: ["CMD", "kafka-topics.sh", "--bootstrap-server", "localhost:9092", "--list"]
interval: 30s
retries: 5
start_period: 5s
kafka3:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
hostname: kafka3
container_name: kafka3
ports:
- "9095:9092"
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka3:29092,PLAINTEXT_HOST://localhost:9095
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
healthcheck:
test: ["CMD", "kafka-topics.sh", "--bootstrap-server", "localhost:9092", "--list"]
interval: 30s
retries: 5
start_period: 5s
kafka-cli:
image: confluentinc/cp-kafka:latest
container_name: kafka-cli
depends_on:
- kafka1
- kafka2
- kafka3
- zookeeper
volumes:
- ./kafka:/opt/kafka
command: tail -f /dev/null
postgres:
image: postgres:13
container_name: postgres
environment:
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_DB: ${POSTGRES_DB}
ports:
- "15432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
producer:
build: ./producer
container_name: producer
depends_on:
- kafka1
- kafka2
- kafka3
environment:
KAFKA_BOOTSTRAP_SERVERS: kafka1:29092,kafka2:29092,kafka3:29092
TOPIC: naver_realestate
command: tail -f /dev/null
volumes:
- ./producer:/app
consumer:
build: ./consumer
container_name: consumer
depends_on:
- kafka1
- kafka2
- kafka3
- postgres
environment:
KAFKA_BOOTSTRAP_SERVERS: kafka1:29092,kafka2:29092,kafka3:29092
TOPIC: naver_realestate
POSTGRES_HOST: postgres
POSTGRES_PORT: 5432
POSTGRES_DB: realestate
POSTGRES_USER: user
POSTGRES_PASSWORD: password
command: python consumer.py
volumes:
- ./consumer:/app
healthcheck:
test: ["CMD-SHELL", "kafka-topics.sh --bootstrap-server kafka1:29092,kafka2:29092,kafka3:29092 --list"]
interval: 10s
retries: 10
kafdrop:
image: obsidiandynamics/kafdrop
container_name: kafdrop
ports:
- "9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka1:29092,kafka2:29092,kafka3:29092"
JVM_OPTS: "-Xms32M -Xmx64M"
depends_on:
- kafka1
- kafka2
- kafka3
redis:
image: redis:7.4
container_name: redis
restart: always
ports:
- "6379:6379"
command: redis-server --appendonly yes
volumes:
- redis-data:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
retries: 5
start_period: 5s
spark:
build: ./spark
container_name: spark
environment:
- SPARK_MODE=master
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_UI_PORT=4040
- SPARK_LOG_LEVEL=INFO
ports:
- "4040:4040"
volumes:
- ./spark:/opt/spark-apps
depends_on:
- kafka1
- kafka2
- kafka3
fastapi:
build: ./fastapi
container_name: fastapi
ports:
- "8000:8000"
depends_on:
- redis
environment:
REDIS_HOST: redis
REDIS_PORT: 6379
volumes:
- ./fastapi:/app
streamlit:
build: ./streamlit
container_name: streamlit
ports:
- "8501:8501"
depends_on:
- fastapi
environment:
API_URL: "http://fastapi:8000"
volumes:
- ./streamlit:/app
volumes:
pgdata:
redis-data:
Kafka Producer: 실시간 데이터 수집
Producer 통해 서울시 API에서 데이터를 가져와 Kafka 토픽에 전송한다.
- producer_parking.py
- 데이터를 가져오는 건 parking.py 파일에서 따로 작성해서 가져왔다.
- API에서 데이터를 가져와 Kafka의 parking_status 토픽에 전송.
- 30초마다 반복 실행하여 최신 주차장 상태 유지.
-
더보기import os
import time
import json
from kafka import KafkaProducer
from parking import get_parking_data
producer = KafkaProducer(
bootstrap_servers="kafka1:29092,kafka2:29092,kafka3:29092",
value_serializer=lambda v: json.dumps(v, ensure_ascii=False).encode("utf-8")
)
TOPIC = "parking_status"
def fetch_and_send_data():
while True:
parking_data = get_parking_data()
if parking_data:
for record in parking_data:
producer.send(TOPIC, record)
producer.flush()
print(f"✅ {len(parking_data)}건의 데이터 Kafka로 전송 완료")
time.sleep(30)
fetch_and_send_data()
- Kafka Producer send()와 flush()
- send()
- 비동기 방식으로 메시지를 전송.
- broker로 메시지를 바로 전송하는 것이 아니라, 내부 버퍼에 쌓아두고 배치를 모아서 보낸다 → 성능 최적화.
- data = producer.send(토픽명, record) 형태로 사용된다.
- flush()
- 동기적으로 작동한다. 즉, 모든 이전에 전송된 메시지가 브로커에 도달할 때까지 대기.
- 버퍼에 남아 있는 모든 메시지를 강제로 전송.
- Kafka가 정상 종료되기 전에 flush()를 호출하지 않으면 일부 메시지가 유실될 가능성 있음.
- producer.close()를 호출하면 자동으로 flush()가 실행됨.
- send()
- 추가로 Producer 사용 시 고려해야할 점
- 이번에는 설정하지 않고 진행했으나, 아래와 같은 사항들을 더 설정하여 고도화할 수 있다!
- Ack 설정
- acks=0 : 빠르지만 데이터 유실 가능성 있음.
- acks=1 : 리더 브로커만 확인하면 성공.
- acks=all : 모든 ISR에 기록될 때 성공.
- 배치 설정
- batch.size : 한 번체 전송할 배치 크기 조절
- linger.ms : 배치 만들기 전 기다리는 시간
- 압축
- compression.type : 네트워크 사용량을 줄일 수 있다. (gzip, snappy, lz4...)
- key 설정
- key를 설정하면 같은 key값을 가진 메시지는 동일한 파티션에 저장되어 순서가 보장된다.
Kafka Consumer: 실시간 데이터 필터링 & Redis 저장
Consumer는 Kafka에서 데이터를 읽고, 실시간 데이터가 제공되는 주차장에 대해서만 Redis에 저장한다.
- consumer_parking.py
- 우선 모든 데이터를 가져와서 수신한 다음, 실시간 데이터를 제공하는 주차장에 대해서만 Redis에 저장
- 주차 가능 공간 계산 후 Redis 업데이트
-
더보기import json
import redis
from kafka import KafkaConsumer
TOPIC = "parking_status"
BOOTSTRAP_SERVERS = "kafka1:29092,kafka2:29092,kafka3:29092"
redis_client = redis.StrictRedis(host="redis", port=6379, db=0, decode_responses=True, charset="utf-8")
consumer = KafkaConsumer(
TOPIC,
bootstrap_servers=BOOTSTRAP_SERVERS.split(","),
value_deserializer=lambda m: json.loads(m.decode("utf-8")),
auto_offset_reset="earliest",
enable_auto_commit=True,
group_id="parking_consumer_group"
)
print("Kafka Consumer 시작")
for message in consumer:
parking_data = message.value
is_realtime = parking_data.get("IS_REALTIME_STATUS_PROVIDED", "N")
if is_realtime != "Y":
continue
parking_name = parking_data.get("PARKING_NAME", "알 수 없음")
capacity = int(parking_data.get("CAPACITY", "0"))
occupied_spots = int(parking_data.get("OCCUPIED_SPOTS", "0"))
available_spots = max(0, capacity - occupied_spots)
# Redis에서 기존 데이터 조회. 기존 값과 비교 후 변경이 있을 때만 Redis 업데이트
prev_spots = redis_client.get(parking_name)
if prev_spots is None or prev_spots == '':
prev_spots = 0
else:
prev_spots = int(prev_spots)
if prev_spots != available_spots:
redis_client.set(parking_name, available_spots)
print(f"🔄 [변경 감지] {parking_name} → 주차 가능 공간: {prev_spots} -> {available_spots}")
else:
print(f"✅ [변경 없음] {parking_name}: {available_spots} 대 가능")
- 추가로 Consumer 사용 시 고려해야할 점
- 오프셋 관리
- auto.offset.reset
- latest : 가장 최근 메시지부터 소비.
- earliest : 가장 처음부터 소비. (테스트로 자꾸 컨테이너를 내렸다 올렸다 하느라 이번에는 earliest로 설정했다.)
- 커밋 방식
- enable.auto.commit=True : 자동으로 오프셋 커밋.
- commitSync() : 메시지를 처리한 후 명시적으로 커밋. 메시지 처리가 완료될 때까지 메시지를 가져온 것으로 간주하면 안되는 경우에 사용됨.
- 파티션 리밸런싱(컨슈머 리밸런싱)
- 컨슈머가 생성/삭제 되면 파티션 할당이 변경됨.
- group.id가 같으면 컨슈머 그룹으로 묶임.
- 컨슈머가 많아지면 자동으로 파티션을 재할당하는 과정에서 메시지 중복 소비 가능.
- max.poll.interval.ms 값을 조정하여 리밸런싱을 줄일 수 있음.
- 오프셋 관리

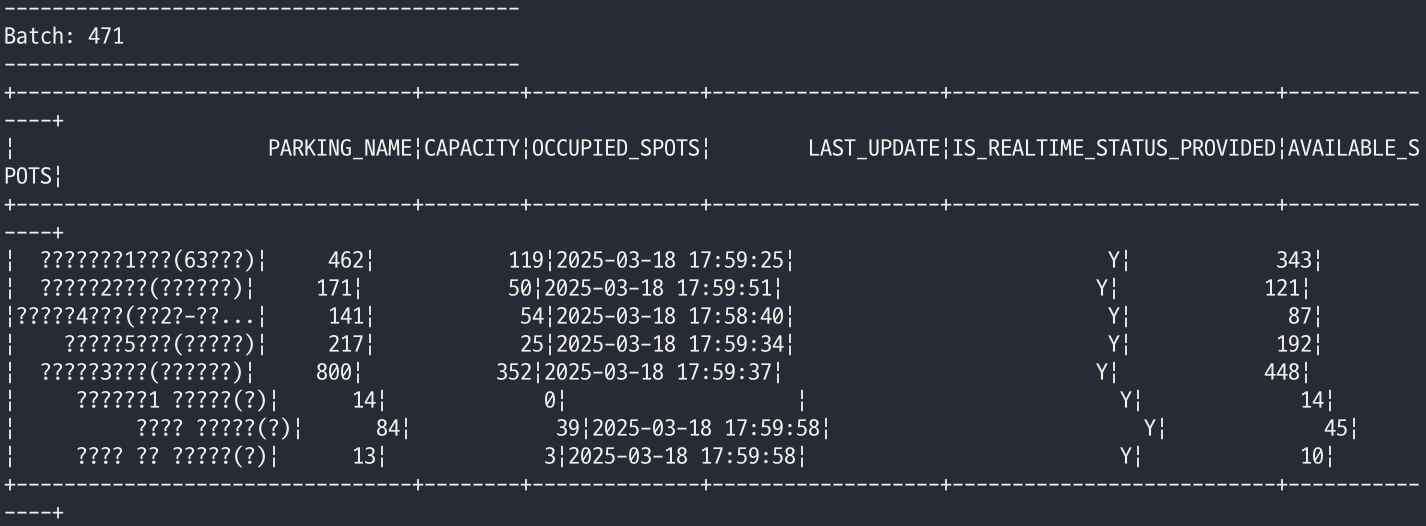
Spark Streaming: 실시간 데이터 분석
- parking_spark.py
- Kafka에서 데이터를 실시간으로 읽고 Spark Streaming으로 분석 가능
(아직 DB 저장 등의 작업은 하지 않았고, 콘솔로만 확인해보았음) -
더보기from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col, when
from pyspark.sql.types import StructType, StringType, IntegerType
# SparkSession 생성
spark = SparkSession.builder \
.appName("KafkaParkingStreaming") \
.config("spark.sql.streaming.forceDeleteTempCheckpointLocation", "true") \
.getOrCreate()
# 데이터 스키마 정의
schema = StructType() \
.add("PARKING_NAME", StringType()) \
.add("CAPACITY", StringType()) \
.add("OCCUPIED_SPOTS", StringType()) \
.add("LAST_UPDATE", StringType()) \
.add("IS_REALTIME_STATUS_PROVIDED", StringType())
# Kafka에서 스트리밍 데이터 읽기
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "kafka1:29092,kafka2:29092,kafka3:29092") \
.option("subscribe", "parking_status") \
.option("startingOffsets", "earliest") \
.load()
df = df.selectExpr("CAST(value AS STRING)")
df = df.withColumn("value", from_json(col("value"), schema)).select("value.*")
# NULL 값 처리
df = df.na.fill({"OCCUPIED_SPOTS": "0", "IS_REALTIME_STATUS_PROVIDED": "N", "CAPACITY": "0"})
# 데이터 타입 변환
df = df.withColumn("CAPACITY", col("CAPACITY").cast(IntegerType()))
df = df.withColumn("OCCUPIED_SPOTS", col("OCCUPIED_SPOTS").cast(IntegerType()))
# 주차 가능 자리 계산 (available_spots = capacity - occupied_spots)
df = df.withColumn("AVAILABLE_SPOTS", when(col("CAPACITY") - col("OCCUPIED_SPOTS") < 0, 0)
.otherwise(col("CAPACITY") - col("OCCUPIED_SPOTS")))
# 실시간 데이터만 필터링
df = df.filter(col("IS_REALTIME_STATUS_PROVIDED") == "Y")
# 콘솔 출력 (테스트)
query = df.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()
- Kafka에서 데이터를 실시간으로 읽고 Spark Streaming으로 분석 가능
FastAPI & Streamlit을 통해 시각화하기
FastAPI API
from fastapi import FastAPI
import redis
app = FastAPI()
redis_client = redis.StrictRedis(host="redis", port=6379, db=0, decode_responses=True)
@app.get("/parking")
def get_parking_data():
parking_keys = redis_client.keys("*")
parking_data = {key: redis_client.get(key) for key in parking_keys}
return {"parking_data": parking_data}
Streamlit 대시보드
import streamlit as st
import requests
response = requests.get("http://fastapi:8000/parking")
data = response.json()["parking_data"]
for name, spots in data.items():
st.write(f"🏢 {name} → 🅿️ 남은 자리: {spots}대")지금은 원하는 지역의 키워드를 입력하면 해당 지역의 주차장 정보 중 실시간 데이터를 지원하는 주차장에 대해
변경되는 현황을 대시보드로 확인할 수 있다.
키워드를 직접 입력할 수 있도록 하는 부분이나,
spark streaming으로 지금 처리는 하고 있으나 따로 활용은 안 하고 있어서
이 부분도 확장 가능한 부분을 어떻게 구축하면 좋을지 구상해 보아야겠다.
그리고 spark streaming을 붙여보긴 했는데 좀 더 구조적인 부분에 대해 공부가 필요하다.
(+ 원하는 지역을 선택하면 해당 지역의 주차장을 보여주는 형태로 수정했다. Spark 활용한 집계 대시보드도 테스트했는데 얼른 올려야지!)
참고
'Lab' 카테고리의 다른 글
| Spark Streaming으로 실시간 주차장 데이터 집계하여 시각화하기 (0) | 2025.04.02 |
|---|---|
| [side-1] 웹 화면에서 사용자 쿼리 받아 유사한 값 출력 보여주기 (0) | 2025.02.19 |
| [side-1] Milvus Collection에 적재된 데이터에서 유사한 값 검색하기 (0) | 2025.01.22 |
| [side-1] LangChain 활용하여 RAG 구축을 위해 Milvus DB 연결 테스트 (0) | 2025.01.21 |
| [side-1] Milvus DB에 텍스트 데이터 임베딩하여 적재하기 (0) | 2025.01.17 |


