
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- amazonlinux
- prometheus
- sparkstreaming
- 루프백주소
- dockercompose
- docker
- 오블완
- milvus
- spark
- jmx-exporter
- RAG
- vectorDB
- kafka
- grafana
- Dag
- Python
- javascript
- MSA
- aiagent
- airflow
- airflow설치
- SQL
- hadoop
- Streamlit
- BigQuery
- pySpark
- ubuntu
- metadabatase
- Redshift
- 설치
- Today
- Total
데이터 노트
Spark Streaming으로 실시간 주차장 데이터 집계하여 시각화하기 본문
자세한 코드 정보는 Github에!
https://github.com/JHYUNN-LEE/2025-side-MyParkingSpot
GitHub - JHYUNN-LEE/2025-side-MyParkingSpot: 서울시 실시간 주차장 현황 대시보드
서울시 실시간 주차장 현황 대시보드. Contribute to JHYUNN-LEE/2025-side-MyParkingSpot development by creating an account on GitHub.
github.com
개요
이전에 실시간 주차장 현황을 보여주는 것에서 발전 시켜서, Spark Streaming으로 실시간 데이터를 집계해서 보여주는 탭을 만들었다.
Kafka → Spark Streaming → PostgreSQL → Streamlit 시각화 흐름으로 구성하였고,
"1시간 단위로 집계해서 지역별로 주차 가능 공간 평균"을 산출했다.
사용 기술 스택
- Kafka : 실시간 주차장 데이터를 전송하는 메시지 브로커
- Spark Structured Streaming : Kafka에서 실시간 데이터를 수신하고 집계
- PostgreSQL : 집계된 데이터를 저장
- Streamlit : 대시보드로 시각화
구현 과정
Kafka에서 실시간 데이터 받기
현재 Producer에서 Kafka Topic(parking_status)로 데이터를 발행하고 있는데, 해당 토픽 데이터는 아래와 같은 구조이다.
{
"REGION": "홍대 관광특구",
"REGION_CODE": "POI007",
"PARKING_NAME": "공유) 9-88(구)",
"PARKING_CODE": "1587410",
"TYPE": "NS",
"CAPACITY": "22",
"OCCUPIED_SPOTS": "0",
"LAST_UPDATE": "2025-03-31 10:16:20",
"IS_REALTIME_STATUS_PROVIDED": "Y",
"PAY_YN": "Y",
"BASE_RATE": "0",
"BASE_TIME": "",
"ADD_RATE": "0",
"ADD_TIME": "",
"LATITUDE": "37.55639535",
"LONGITUDE": "126.9293177"
}이 데이터 중 실시간 데이터를 제공하는 주차장과 필요한 항목 값으로만 필터링 했다.
- 필터링 값
| REGION | 지역명 |
| REGION_CODE | 지역 코드 |
| PARKING_NAME | 주차장명 |
| CAPACITY | 수용 가능 대수 |
| OCCUPIED_SPOTS | 현재 주차 대수 |
| IS_REALTIME_STATUS_PROVIDED | 실시간 데이터 제공 여부 |
Spark Streaming으로 집계 처리
Kafka의 메시지를 실시간 스트리밍으로 읽고, 집계 처리한다.
주요 처리 내용
- UTF-8 디코딩 및 JSON 파싱
- 실시간 데이터 여부 필터링
- 주차 가능 대수 계산 : AVAILABLE_SPOTS = CAPACITY - OCCUPIED_SPOTS
- Kafka 메시지의 timestamp를 RECEIVED_AT으로 활용하여 집계 기준 시간으로 사용
- window와 watermark를 활용한 1시간 단위 집계
1시간 단위 집계 코드
# ...생략
clean_df = parsed_df.filter(col("IS_REALTIME_STATUS_PROVIDED") == "Y") \
.na.fill({"CAPACITY": 0, "OCCUPIED_SPOTS": 0}) \
.withColumn("AVAILABLE_SPOTS", when(
col("CAPACITY") - col("OCCUPIED_SPOTS") < 0, 0
).otherwise(col("CAPACITY") - col("OCCUPIED_SPOTS"))) \
.withColumnRenamed("timestamp", "RECEIVED_AT") \
.withWatermark("RECEIVED_AT", "1 hour")
# 생략...# ...생략
agg_df = clean_df.groupBy(
window(col("RECEIVED_AT"), "1 hour"),
col("REGION"),
col("REGION_CODE")
).agg(
avg("AVAILABLE_SPOTS").alias("AVG_AVAILABLE_SPOTS")
)
# 생략...
이 작업을 하면서 window / wateramark 에 대해 너무 헷갈렸다..
Spark Window / Watermark
알아야 하는 포인트는 크게 5가지 정도가 있다.
| Event Time | 데이터가 실제로 발생한 시간 |
| Processing Time | Spark가 데이터를 처리하는 시간 |
| Window Duration | 데이터를 집계하는 시간 범위 (ex. 10분 단위) |
| Slide Duration | 윈도우가 얼마나 자주 움직일지 (ex. 5분마다) |
| Watermark | 지연 허용 시간 (이 시간보다 늦게 온 데이터는 무시) |
window와 watermark는 event time 기반이고, 그렇기 때문에 데이터에 timestamp 필드가 있어야 한다.
slide의 경우, 지정하지 않으면 window와 동일한 간격으로 슬라이딩 된다. (겹치지 X)
-> 집계 주기가 명확하고 중복 없이 처리하고 싶다면 sliding 생략해도 되지만 중첩 집계가 필요하다면 sliding을 명시해주어야 한다.
내가 작성한 코드로 살펴보자.
코드를 보면 slide duration 간격을 따로 지정하지 않았다.
agg_df = clean_df.groupBy(
window(col("RECEIVED_AT"), "1 hour"), # 생략...
즉 윈도우랑 동일하게 움직이게 되고, [11:00 ~ 12:00] [12:00 ~ 13:00] 과 같은 형태로 작동하게 된다.
watermark의 경우, 이렇게 설정 되어 있는데, RECEIVED_AT 기준으로 최대 1분 늦게 도착한 데이터까지 허용된다.
(테스트 문제로 1 minute으로 짧게 설정했었다.)
clean_df = parsed_df.filter(col("IS_REALTIME_STATUS_PROVIDED") == "Y") \
# ...생략...
.withWatermark("RECEIVED_AT", "1 minute")
헷갈리니 가정을 통해 살펴보자.
현재 시각이 14:00 이라고 가정했을 때, window는 정각을 기준으로 하며 정각 기준 13:00 이상 ~ 14:00 미만이다.
그리고 1분 더 기다렸다가 14:01 이후에는 spark가 13:00 ~ 14:00 시간대의 집계를 마무리하고 결과를 도출한다.
14:00에 발생한 이벤트는 이 window에 포함되지 않고 [14:00 ~ 15:00] 윈도우에 포함된다.
| 집계 대상 윈도우 | [13:00 ~ 14:00] |
| 포함되는 데이터 | RECEIVED_AT >= 13:00:00 AND < 14:00:00 |
| Watermark 대기 시간 | 1분 |
| 집계 실행 시점 | 14:01:00 |
| 결과 저장 시점 | 보통 14:01 이후 1~2초 내 (Spark가 처리 끝내는 시점) |
또 헷갈렸던 건 Spark 실행 시간이 정각이 아닐 때이다.
Spark Streaming 실행을 14:23 과 같이 이렇게 애매한 시간에 했다고 가정해보자.
Spark의 window는 현재 시간 기준으로 시작하는 것이 아닌, event time 기준이기 때문에
timestamp 필드(RECEIVED_AT)의 값을 고정된 시간 경계(매 정시, 1시, 2시, 3시, ...)로 잘라서 윈도우를 만든다.
14:23에 Spark를 실행하면 아래와 같은 데이터들이 들어왔을 때 window는 이렇게 생성된다.
| Kafka 도착 시각 | RECEIVED_AT | Window |
| 14:23:10 | 14:22:59 | [14:00 ~ 15:00] |
| 14:23:20 | 13:59:55 | [13:00 ~ 14:00] |
| 14:23:30 | 14:00:01 | [14:00 ~ 15:00] |
드디어 어느 정도 이해한 것 같다..ㅠ
집계 데이터 PostgreSQL 적재
집계한 데이터를 PostgreSQL에 적재한다.
테이블 생성
CREATE TABLE parking.parking_hourly_avg (
id serial PRIMARY KEY,
region varchar(255),
region_code varchar(50),
hour timestamp without time zone, -- spark에서 KST로 시간을 맞춰줬다.
avg_available_spots double precision,
created_at timestamp without time zone DEFAULT (CURRENT_TIMESTAMP AT TIME ZONE 'Asia/Seoul')
);- 적재 형태
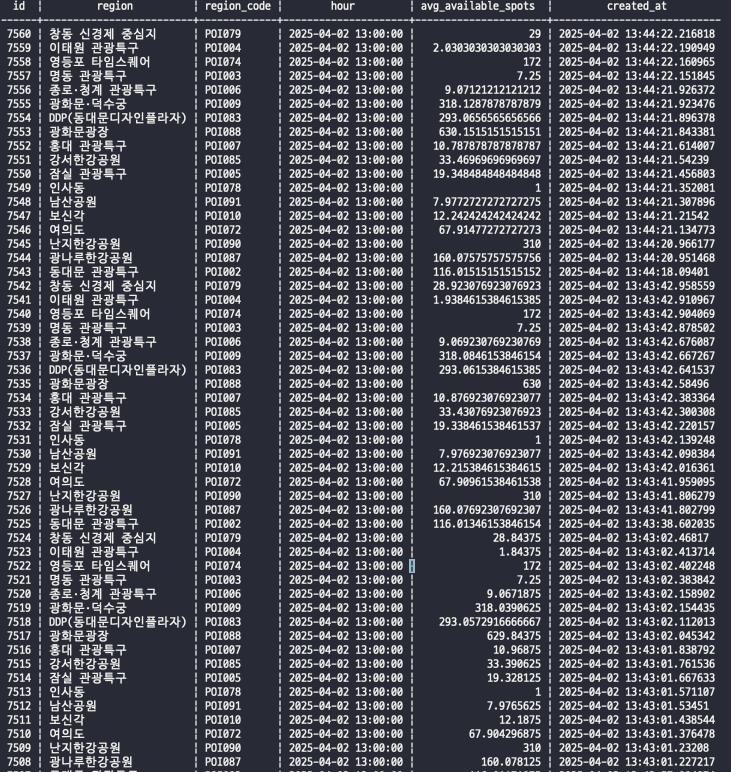
def write_to_postgres(batch_df, epoch_id):
batch_df.write \
.format("jdbc") \
.option("url", f"jdbc:postgresql://{os.getenv('POSTGRES_HOST')}:{os.getenv('POSTGRES_PORT')}/{os.getenv('POSTGRES_DB')}") \
.option("dbtable", "parking.parking_hourly_avg") \
.option("user", os.getenv("POSTGRES_USER")) \
.option("password", os.getenv("POSTGRES_PWD")) \
.option("driver", "org.postgresql.Driver") \
.mode("append") \
.save()
# ... 생략 ...
agg_df.writeStream \
.outputMode("update") \
.foreachBatch(write_to_postgres) \
.start() \
.awaitTermination()중간 값을 확인 하기 위해 outputMode를 update로 설정했다.
Streamlit으로 시각화
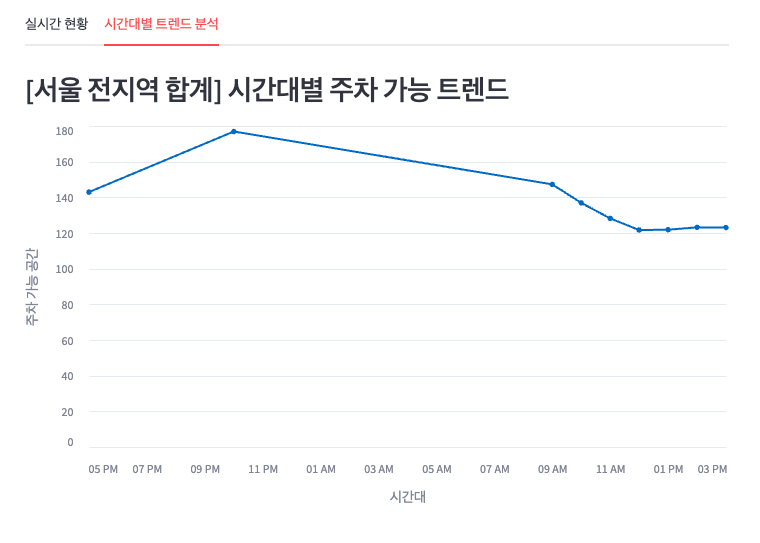
PostgreSQL에 저장된 시간대별 평균 주차 가능 공간 데이터를 조회하여, 크게 두 가지로 시각화했다.
- 전체 지역에 대한 시간대별 평균 주차 가능 대수
- 지역별 시간대별 주차 가능 대수

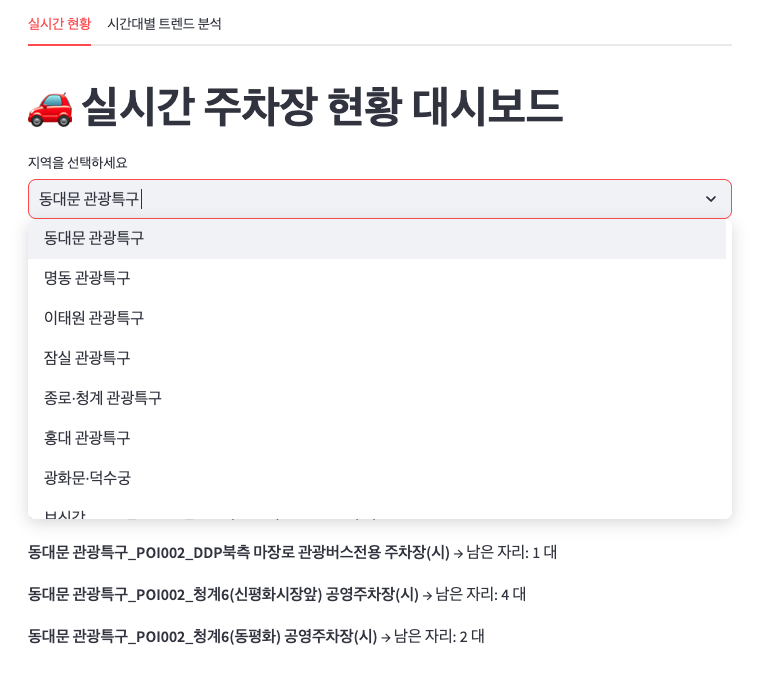
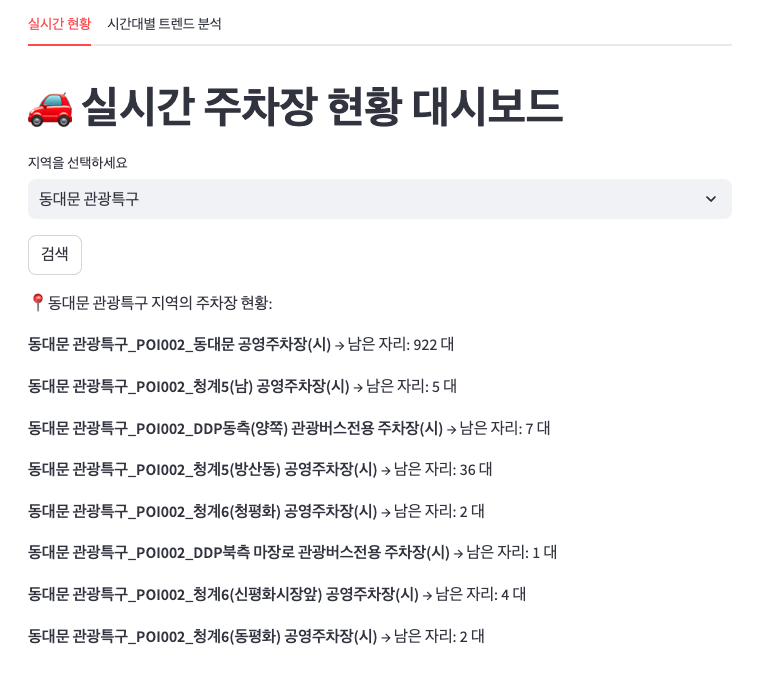
그리고 이전에 작업한 실시간 현황 대시보드도 수정했는데,
실시간 데이터를 제공하는 주차장 목록을 기준으로 드롭다운으로 선택할 수 있게 만들었다.
그리고 탭을 구분해서 실시간 탭과 집계 탭으로 나누었다.
Kafka랑 Spark Streaming 구현하면서 기본적인 구조와 개념을 직접 적용해보고 아키텍처를 만들어서 시각화까지 해보았다.
역시 직접 만들어보는게 더 이해가 잘 가는 것 같다.
앞으로는 Kafka나 Spark에서 설정하는 세부적인 요소들에 대해 공부하고 그에 따른 성능 등을 체크하면서 고도화 해보아야겠다.
기본 개념도 보다 탄탄히 하면 좋을 듯.
'Lab' 카테고리의 다른 글
| Kafka, Spark, Redis를 활용한 실시간 주차장 현황 대시보드 구축하기 (2) | 2025.03.18 |
|---|---|
| [side-1] 웹 화면에서 사용자 쿼리 받아 유사한 값 출력 보여주기 (0) | 2025.02.19 |
| [side-1] Milvus Collection에 적재된 데이터에서 유사한 값 검색하기 (0) | 2025.01.22 |
| [side-1] LangChain 활용하여 RAG 구축을 위해 Milvus DB 연결 테스트 (0) | 2025.01.21 |
| [side-1] Milvus DB에 텍스트 데이터 임베딩하여 적재하기 (0) | 2025.01.17 |


